绿软下载站:请安心下载,绿色无病毒!
最近更新热门排行

本地下载文件大小:.00 M
高速下载需优先下载高速下载器
python多线程爬取人人影视视频源码。python经典源码爬取系列,本次带来的是能够爬取人人影视平台视频资源的源码数据信息,支持关键词智能搜索功能,可以快速搜索爬取想要的人人影视视频资源。源码直接编辑即可生成爬取程序,需要在编辑平台上进行搭建,感兴趣的朋友们不妨试试吧!

此程序可爬取大部分人人影视数据,具体bug还没测试
安装requirements
pip install -r requirements.txt
修改settings.json中的数据(当前为默认设置)
布尔值只能设置为布尔值,true为需要爬取的数据,false则不爬取
pageNum:可选择"1-737"多页面 或者 "2" 单页面爬取
level:可选择只爬取 "e" ,也可以选择"abe","abc"等多种组合爬取,如果选择"all",则会爬取一些暂无分级的影视信息
export:默认为导出csv格式,当前仅支持mongodb,如有需要,自行修改下列代码替换"csv"
{
"db": "mongodb",
"host": "localhost",
"port": 27017,
"username": "",
"password": "",
"dbname": "rrys",
"table": "rrys"
}
defanalyze(u):
try:
url=baseurl+u
html=pq(requests.get(url, headers=headers).content.decode())
# 获取标题和剧种
t=html(".resource-tit h2").text()
title=re.search("【(.*)】《(.*)》", t).groups()
# 获取影视分级
items=html('.level-item img').attr('src')
level=get_level(items, info["level"])
# 如果返回的分级为false则跳过这条
iflevel==False:return
# 获取主要信息
main_info=get_info(html)
# 获取剧种
if"dramaType"inresult_info:
main_info["dramaType"]=title[0]
# 获取评分
if"score"inresult_info:
main_info["score"]=get_score(u[-5:])
if'url'inresult_info:
main_info['url']=url
# 获取影片封面
if"imgurl"inresult_info:
main_info['imgurl']=html('.imglink a').attr('href')
# 获取本站排名
if"rank"inresult_info:
main_info["rank"]=re.search("本站排名:(\d*)", html(".score-con li:first-child .f4").text()).group(1)
# 获取简介
if"introduction"inresult_info:
main_info["introduction"]=html(".resource-desc .con:last-child").text()
result={}
# 写入标题和分级
result["title"]=title[1]
result["level"]=level
# 遍历main_info,只写入有效数据
forkey, valueinresult_info.items():
try:
result[key]=main_info[key]
except:
result[key]='暂无'
print(result['title'])
# 写入文件
ifexport=='csv':
wirtecsv([iforiinresult.values()])
else:
mycol.insert_one(result)
exceptException as e:
throw_error(e)
analyze(u)
defmain(num):
try:
url=baseurl+"/resourcelist/?page={}".format(num)
doc=pq(requests.get(url, headers=headers).content.decode())
urls=doc(".fl-info a").items()#遍历a标签
ifinfo['threads']:
foriinurls:
Thread(target=analyze,args=(i.attr("href"),)).start()
else:
foriinurls:
analyze(i.attr("href"))
time.sleep(1)
exceptException as e:
throw_error(e)
main(num)
 乌云极简云盘源码V1.1免费版7-12
乌云极简云盘源码V1.1免费版7-12 PHP文字表情包制作网站源码10-25
PHP文字表情包制作网站源码10-25 GIt离线储存库管理器GitAheadv2.5.8 官方版7-23
GIt离线储存库管理器GitAheadv2.5.8 官方版7-23 超级井字棋【附源码】12-17
超级井字棋【附源码】12-17 新域名缩短认证V标志生成源码2018最新版9-12
新域名缩短认证V标志生成源码2018最新版9-12 码云企业版( Git@OSC)v8.15.2 最新版1-6
码云企业版( Git@OSC)v8.15.2 最新版1-6 开源CF网截过362易语言源码教学版11-8
开源CF网截过362易语言源码教学版11-8 每日心灵毒鸡汤PHP网站源码程序绿色免费版11-26
每日心灵毒鸡汤PHP网站源码程序绿色免费版11-26 全网视频搜索VIP解析工具源码8-21
全网视频搜索VIP解析工具源码8-21 3款刺激战场腾讯模拟器辅助源码8-21
3款刺激战场腾讯模拟器辅助源码8-21 会员影视中心全网VIP视频解析源码v1.0最新在线版 | .33MB
会员影视中心全网VIP视频解析源码v1.0最新在线版 | .33MB 蓝奏网盘解析调用代码免费最新版 | .00MB
蓝奏网盘解析调用代码免费最新版 | .00MB 伯乐PHP个人在线自动发卡网源码v3.1 | 5.9M
伯乐PHP个人在线自动发卡网源码v3.1 | 5.9M asp.net客户关系管理系统完整源码2017最新版 | 22.6M
asp.net客户关系管理系统完整源码2017最新版 | 22.6M jquery特效编写js库v2.0.0 | .09MB
jquery特效编写js库v2.0.0 | .09MB electron-huaban画板下载工具最新版 | .67MB
electron-huaban画板下载工具最新版 | .67MB TamTam CVS SCCv2.5.02.2088官方版 | 3.4M
TamTam CVS SCCv2.5.02.2088官方版 | 3.4M 让你的照片动起来会说话纯前端网站源码 | .72MB
让你的照片动起来会说话纯前端网站源码 | .72MB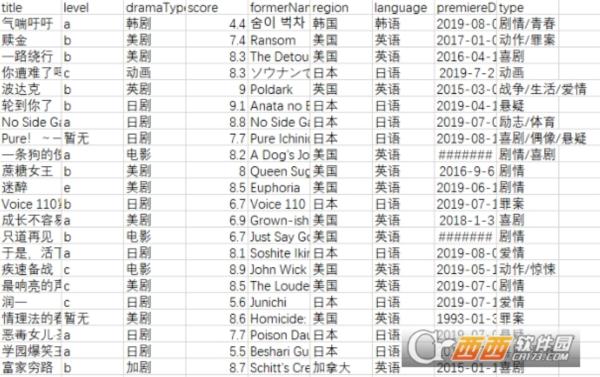
 由叔全网首发YY抢麦协议源码最新易语言版
由叔全网首发YY抢麦协议源码最新易语言版 表白墙网自适应源码带后台免费版
表白墙网自适应源码带后台免费版 E4A影视app源码最新版
E4A影视app源码最新版 七夕超级好看表白源码(让你的表白不一样)表白神器
七夕超级好看表白源码(让你的表白不一样)表白神器 电视迷影视网源码(带20000部影片数据库采集全站)附本地搭建苹果CMS教程
电视迷影视网源码(带20000部影片数据库采集全站)附本地搭建苹果CMS教程 YY全自动蹲点加好友软件源码完整免费版
YY全自动蹲点加好友软件源码完整免费版 e4a源码修复工具V2.1.30
e4a源码修复工具V2.1.30

















软件评论 请自觉遵守互联网相关政策法规,评论内容只代表网友观点,与本站立场无关!
网友评论