绿软下载站:请安心下载,绿色无病毒!
最近更新热门排行

本地下载文件大小:41.9M
高速下载需优先下载高速下载器
TesseractOCR,可以直接将图片中的文字进行识别,其最新版本3.0已经支持中文OCR,并提供了一个命令行工具,转换成文本信息。tesseract-ocr官方下载据说曾经的图像识别能力排名第三。tesseract-ocr中文版可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文)。 Tesseract最初由HP公司开发,后来由Google维护,目前发布在Googel Project上。
windows下的安装非常简单,直接安装可执行程序即可。当你选择安装各类语言之时,则需要一个稍微耗时的等待操作,比如下图中所示的信息:
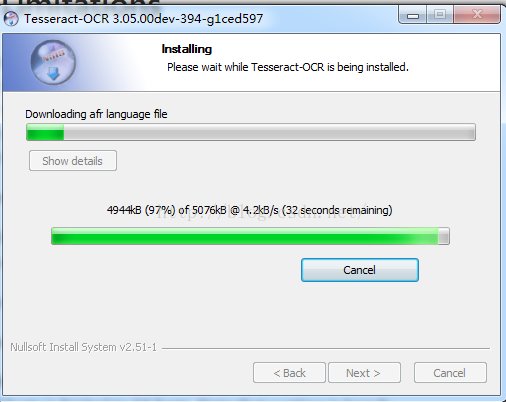
下载完后进行安装,默认情况下安装程序会给你配置系统环境变量,以指向安装目录(之后可以通过DOS界面在任意目录运行tesseract)。安装完成后目录如下:

附录:
tessdata 目录存放的是语言字库文件,和在命令行界面中可能用到的参数所对应的文件. 这个安装程序默认包含了英文字库。
使用Tessract-OCR引擎识别验证码
打开DOS界面,输入tesseract:

如果出现如上输出,表示安装正常。
我准备了一张验证码code.jpg放在D盘根目录下 ,上图:
,上图:

结果为:

附录:
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
 天天码字PC客户端2.0.0官方版 | 129.0M汉王文豪7600全能专业版官方完全版 | 161.1M
天天码字PC客户端2.0.0官方版 | 129.0M汉王文豪7600全能专业版官方完全版 | 161.1M wps2019便携版U盘版v10.1.0.7311精简版 | 82M
wps2019便携版U盘版v10.1.0.7311精简版 | 82M Luban Reader鲁班报表V1.0官方版 | 30.9M
Luban Reader鲁班报表V1.0官方版 | 30.9M 云核销appv5.0.4安卓版 | 6M
云核销appv5.0.4安卓版 | 6M Aide PDF to DWG Converterv11.0 官方免费版 | 6.6M
Aide PDF to DWG Converterv11.0 官方免费版 | 6.6M Uzer.Me云端超级应用空间V1.0.1.0官方最新版 | 65.6M
Uzer.Me云端超级应用空间V1.0.1.0官方最新版 | 65.6M 星韵全能抽奖系统v4.20 中文版 | 15.9M
星韵全能抽奖系统v4.20 中文版 | 15.9M








 技聊PC版1.0.0.15官方版
技聊PC版1.0.0.15官方版 AnLi微信机器人【附教程】v3.2最新版
AnLi微信机器人【附教程】v3.2最新版 风影苏宁营销助手1.0官方版
风影苏宁营销助手1.0官方版 多可电子档案管理系统v6.1.9.4官方版
多可电子档案管理系统v6.1.9.4官方版 九鼎V17商超收银系统17.0.0.1官方版
九鼎V17商超收银系统17.0.0.1官方版 定向井设计及计算软件1.0
定向井设计及计算软件1.0 穿云箭工具箱1.0.0.3官方版
穿云箭工具箱1.0.0.3官方版

















软件评论 请自觉遵守互联网相关政策法规,评论内容只代表网友观点,与本站立场无关!
网友评论