绿软下载站:请安心下载,绿色无病毒!
最近更新热门排行

本地下载文件大小:.00 M
高速下载需优先下载高速下载器
python爬取微博评论源码,由论坛大神原创制作的一个爬取程序,可以爬取微博评论,用户可以单独搜索某个博主的微博,搜索历史时间线,快速爬取获取目标微博下的全部评论,并直接导入到txt文档内。本次放出python爬取微博评论工具源码下载,感兴趣的朋友们不妨试试吧!

打开网址[https://m.weibo.cn/detail/4478512314460101]
点击万能的F12
点击:->网络->XHR->hotflow.....->预览
网址:[https://m.weibo.cn/comments/hotflow?id=4478512314460101&mid=4478512314460101&max_id_type=0]
已经可以确定这个是评论的json接口了
然后看第二页有什么区别
往下拉,看第二页
看来数据没什么区别
第一页网址:[https://m.weibo.cn/comments/hotflow?id=4478512314460101&mid=4478512314460101&max_id_type=0]
第二页网址:[https://m.weibo.cn/comments/hotflow?id=4478512314460101&mid=4478512314460101&max_id_type=0&max_id=17250816281250492]
咦,第一页和第二页多出来一个max_id参数(后面其他页数也是这里就不做演示了)
看一下第一页数据中是否有max_id
果然有max_id,还是第二页的(看懂了一切)
那就是说:第二页的max_id在第一页中,第三页的在第二页中,以此类推
import requests
import json
import re
import os
'''
说明:请添加第11行的cookie,修改第26行的保存路径
作者:帅气逼人的钢铁直男---幻夜
'''
headers = {#请求标题头
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4086.0 Mobile Safari/537.36',
'cookie':''#请填写自己的cookie
}
id = input("请输入ID:")#获取ID
if id == "":#当ID为空停止脚本
print('再见')
os._exit(0)#停止脚本
ret = requests.get('https://m.weibo.cn/detail/'+id,headers = headers).text#获取网页内容
if '出错了' in str(ret):#网页出错停止脚本
print('ID不存在')
os._exit(0)#停止脚本
title = input("请输入保存文件名字:")#输入保存文件名字
if title == "":#为空停止脚本
print('再见')
os._exit(0)#停止脚本
max_id = False#定义变量
path = "C:\\Users\\win10\\Desktop\\python\\爬虫\\"+title+".txt"#自己修改文件路径
if os.path.exists(path):#当文件存在时删除,为了不重复
os.remove(path)#删除
page_end = 10#爬取页数,自己修改
page_start = 1
u = 1
while page_start<page_end:#当start小于end时进行循环
if max_id == False:#因为微博第一页和其他页的参数不一样所以需要区分开来
url = "https://m.weibo.cn/comments/hotflow?id="+id+"&mid="+id+"&max_id_type=1"#第一页不包含max_id
json = requests.get(url)#访问评论json数据
else:
url = "https://m.weibo.cn/comments/hotflow?id="+id+"&mid="+id+"&max_id="+str(max_id)+"&max_id_type=0"
json = requests.get(url,headers = headers)#访问评论json数据
json = json.json()#转化数据
max_id = json['data']['max_id']#第二页的max_id在第一页中 第三页在第二页中...以此类推
jsons = json['data']['data']
page_start = page_start+1#自增
for j in jsons:
text = j['text']
text = re.sub(r'<(.+?)>','',text)#删除表情包
with open(path,"a+",encoding = 'utf-8') as f:
f.write(text+'\n\n')
print("第"+str(u)+"条评论完成")
u = u+1
print('完成')
3月20日消息 天眼查数据显示,3月19日,微博的运营主体——北京微梦创科网络技术有限公司发生多项工商变更。
其中,刘运利退出法定代表人、经理、执行董事,新增微博代理首席财务官兼高级副总裁曹菲为法定代表人、董事长、经理;新增黄争取、谷海燕为董事。此外,注册资本从原来的5.55亿增至约5.6亿,增幅为1.01%,其经营范围也发生了变更。
北京微梦创科网络技术有限公司成立于2010年8月,天眼查股东信息显示,王巍、刘运利分别持股29.70%,为公司最大股东。
 CakePHP网页应用开发环境源码v2.9.51-25
CakePHP网页应用开发环境源码v2.9.51-25 个人自助发卡系统源码轻量版4-15
个人自助发卡系统源码轻量版4-15 实现百度的鼠标移入图片抖动的特效5-15
实现百度的鼠标移入图片抖动的特效5-15 EXUI迅直播网盘磁力界面UI源码10-19
EXUI迅直播网盘磁力界面UI源码10-19 抖音时钟原生JS文字钟源码html动态版11-11
抖音时钟原生JS文字钟源码html动态版11-11 Emlog响应式Coffee主题(个人博客系统)9-14
Emlog响应式Coffee主题(个人博客系统)9-14 HYBBS轻论坛网站源码v2.1.39-29
HYBBS轻论坛网站源码v2.1.39-29 ZE语言中文系统/安卓开发工具V1.0绿色版8-20
ZE语言中文系统/安卓开发工具V1.0绿色版8-20 layuiAdmin2020后台管理模板v1.4 学习版5-7
layuiAdmin2020后台管理模板v1.4 学习版5-7 天天影视E4A开源美化版8-6
天天影视E4A开源美化版8-6 ptcms采集系统【附安装教程】 | 17.7M
ptcms采集系统【附安装教程】 | 17.7M ptcms小说自动采集系统源码(附app) | 4.3M
ptcms小说自动采集系统源码(附app) | 4.3M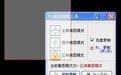 三胖易语言屏幕录像源码免费版 | 1.0M
三胖易语言屏幕录像源码免费版 | 1.0M 蓝奏云解析易语言和php源码最新版 | .24MB
蓝奏云解析易语言和php源码最新版 | .24MB 苹果cms全功能仿三贼模板 | 1.3M
苹果cms全功能仿三贼模板 | 1.3M 王者荣耀皮肤iApp源码最新版 | .53MB
王者荣耀皮肤iApp源码最新版 | .53MB 网站版面自适应设定源码最新版 | 3.3M
网站版面自适应设定源码最新版 | 3.3M 很好看的宇宙人404模板源码免费版 | .32MB
很好看的宇宙人404模板源码免费版 | .32MB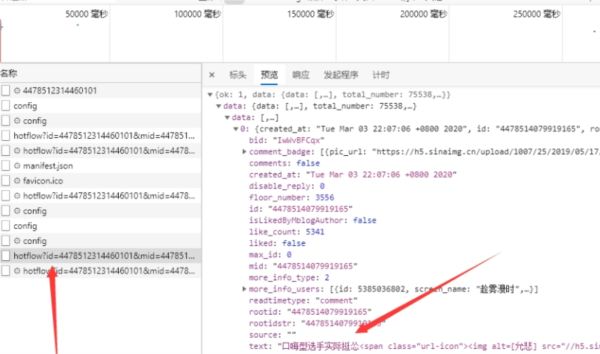
 最新球球大作战代点源码2016在线辅助工具
最新球球大作战代点源码2016在线辅助工具 京东图床外链瀑布php源码最新版
京东图床外链瀑布php源码最新版 荒野行动D3D11HOOK透视上色源码2018绿色版
荒野行动D3D11HOOK透视上色源码2018绿色版 锁机软件易语言源码免费版
锁机软件易语言源码免费版 MATLAB人脸识别源码免费版
MATLAB人脸识别源码免费版 2016最新易语言刷屏骂人软件源码免费版
2016最新易语言刷屏骂人软件源码免费版 jquery特效编写js库v2.0.0
jquery特效编写js库v2.0.0
















软件评论 请自觉遵守互联网相关政策法规,评论内容只代表网友观点,与本站立场无关!
网友评论